Abstract:
Variable projection is a classical technique for separable nonlinear least-squares problems, in which variables that enter linearly are eliminated exactly, yielding a reduced nonlinear problem. By expressing this framework as a particular instance of a broader class of bilevel optimization problems, we develop a constrained variable-projection framework for data-science models, where the remaining variables are subject to convex constraints and the eliminated variables arise from a lower-level least-squares problem. In particular, by interpreting variable projection as a collapsed bilevel optimization problem, we derive exact reduced-gradient formulas compatible with automatic differentiation and propose a conditional-gradient algorithm for the resulting constrained reduced problem.
...
Read more
Abstract:
We study the problem of emergency operation center placement in disaster response, where a minimal number of hubs must be selected to ensure timely coverage of all affected locations. This task can be formulated as a minimum dominating set problem on a graph encoding reachability within a target response time. We propose a hybrid quantum-classical approximation framework that leverages neutral-atom quantum computers as independent set samplers. Candidate dominating sets are constructed from both small maximal independent sets and complements of large independent sets, and are subsequently refined via a lightweight classical procedure.
...
Read more
Paper accepted @ Transactions on Machine Learning Research (TMLR)
Abstract:
Neural networks for image classification are vulnerable to adversarial attacks; an imperceptible perturbation to an image can cause a change in classification. Standard attack algorithms use explicit or approximate partial derivative information with respect to the input data. Here, we explore the idea of using a less expensive, universal affine surrogate. We find that this approach can match, or even outperform, a traditional gradient-based algorithm. Training the affine attack model leads us naturally towards transformations that are close to low rank, reflecting the structure of the problem.
...
Read more
Abstract:
Deep learning-based methods have shown remarkable effectiveness in solving PDEs, largely due to their ability to enable fast simulations once trained. However, despite the availability of high-performance computing infrastructure, many critical applications remain constrained by the substantial computational costs associated with generating large-scale, high-quality datasets and training models. In this work, inspired by studies on the structure of Green’s functions for elliptic PDEs, we introduce Neural-HSS, a parameter-efficient architecture built upon the Hierarchical Semi-Separable (HSS) matrix structure that is provably data-efficient for a broad class of PDEs.
...
Read more
Abstract:
Quantum architectures based on neutral atoms have gained significant attention in recent years as specialized computational machines due to their ability to directly encode the independent set constraint on graphs, exploiting the Rydberg blockade mechanism. In this work, we address the Drone Delivery Packing Problem via a hybrid quantum-classical framework leveraging a neutral-atom quantum processing unit (QPU). We reformulate the optimization task as a graph-partitioning problem based on the independent sets (ISs) of a scheduling graph that encodes delivery incompatibilities.
...
Read more
Abstract:
In many scientific contexts, obtaining complete observations of PDE coefficients and solutions proves expensive, hazardous, or unfeasible. Recent diffusion-based approaches can reconstruct fields from incomplete data, yet require fully observed examples during training. We present Ambient Physics, a framework enabling models to learn joint distributions of coefficient-solution pairs using only partial observations, without needing any complete training examples. Our key insight involves randomly masking already-observed measurements during training and supervising predictions on them.
...
Read more
Joint work with Sidhant Sundrani and Pasquale Minervini. We propose LLRC, a gradient-based method for optimally selecting per-layer ranks when compressing large language models via low-rank decomposition, consistently outperforming competing rank-selection methods across various compression rates on reasoning and QA benchmarks.
Papers accepted @ ICLR 2026 and WWW 2026
Excited to share that three papers from my group have been recently accepted. Huge congrats to Kevin Zhang and Harris Abdul Majid for leading these projects!
Abstract:
In this article, we introduce eigenvector centralities for higher-order multilayer networks and suggest to use nonnegative tensor train decomposition for fast computations of dominant eigenvectors of multi-homogeneous maps via power iterates. The analysis of the approximation error for using nonnegative tensor train instead of the original nonnegative tensor is presented.
Please cite this work as: @article{shcherbakova2025fast, title={Fast Computation of Eigenvector Centralities for Multilayer Networks with Nonnegative Tensor Train}, author={Shcherbakova, Elizaveta M.
...
Read more
Abstract:
Approaches for compressing large-language models using low-rank decomposition have made strides, particularly with the introduction of activation and loss-aware SVD, which improves the trade-off between decomposition rank and downstream task performance. Despite these advancements, a persistent challenge remains–selecting the optimal ranks for each layer to jointly optimise compression rate and downstream task accuracy. Current methods either rely on heuristics that can yield sub-optimal results due to their limited discrete search space or are gradient-based but are not as performant as heuristic approaches without post-compression fine-tuning.
...
Read more
PhD Position: Machine Learning for Fusion Energy Plasma Turbulence
I am looking for a PhD student to work on an exciting project at the intersection of machine learning, computational physics, and fusion energy research.
Project:
Machine Learning for Multi-Fidelity Turbulent Transport Modelling in Tokamak Plasmas
Predicting turbulence and transport in magnetically confined plasmas is one of the major challenges in developing fusion energy. High-fidelity simulations based on nonlinear gyrokinetic theory can accurately model turbulent behaviour in tokamaks but are extremely computationally expensive, often requiring hundreds of thousands of CPU-hours for a single run.
To make large-scale predictive modelling feasible, researchers use simplified, lower-fidelity models such as linear gyrokinetics or gyro-fluid approximations, but these come at the cost of reduced accuracy.
What You’ll Do
This PhD project will explore how machine learning can bridge these fidelity levels, combining the accuracy of high-fidelity models with the efficiency of reduced ones. The work will involve:
Comparing and integrating different turbulence models to identify where simplified approaches remain valid
Developing machine learning-based correction models to improve predictions from lower-fidelity simulations
Investigating whether machine learning can reconstruct high-resolution plasma behaviour from lower-resolution simulations, guided by physical insight into nonlinear interactions
Exploring how recent advances in large-scale deep generative modelling, including diffusion-based and autoregressive architectures, can be adapted to accelerate PDE solvers and plasma turbulence simulations
Prerequisites
Background in physics, applied mathematics, or computer science
Experience and enthusiasm for using deep learning software such as PyTorch (or equivalent frameworks) are essential
Supervision and Funding
Supervisors: Francesco Tudisco (University of Edinburgh), Bhavin Patel (UKAEA, Oxford)
Duration: 4 years full-time
Full scholarship covering tuition fees and stipend
Students will be based at the Culham Centre for Fusion Energy in Oxfordshire, with regular visits to the University of Edinburgh
Interviews for shortlisted candidates: Expected during the week of 19th January 2025
The application portal will ask you to fill in a research proposal (optional). This can be used as an occasion to write about your scientific interests, why the project fits with those, and any ideas you have for things you would like to do within the PhD project. Please keep the content short and crisp.
For informal inquiries, feel free to reach out to me directly
Related References
[1] P. Rodriguez-Fernandez et al., Nonlinear gyrokinetic predictions of SPARC burning plasma profiles enabled by surrogate modeling 2022 Nucl. Fusion 62 076036
[2] J. Candy et al., Multiscale-optimized plasma turbulence simulation on petascale architectures. Computers & Fluids 188 (2019): 125-135.
[3] G. Staebler et al., Quasilinear theory and modelling of gyrokinetic turbulent transport in tokamaks. Nuclear Fusion 64.10 (2024): 103001.
[4] C. Bourdelle et al., A new gyrokinetic quasilinear transport model applied to particle transport in tokamak plasmas. Physics of Plasmas 14.11 (2007).
[5] W. A. Hornsby et al., Gaussian process regression models for the properties of micro-tearing modes in spherical tokamaks. Physics of Plasmas 31.1 (2024).
[6] V. Gopakumar et al., Plasma surrogate modelling using Fourier neural operators. Nuclear Fusion 64.5 (2024): 056025.
[7] L. Zanisi et al., Efficient training sets for surrogate models of tokamak turbulence with active deep ensembles. Nuclear Fusion 64.3 (2024): 036022.
[8] H. Wang et al, Recent Advances on Machine Learning for Computational Fluid Dynamics: A Survey, arxiv:2408.12171
[9] T. Li et al, Synthetic Lagrangian turbulence by generative diffusion models, Nature Machine Intelligence 2024
[10] I. Price et al, Probabilistic weather forecasting with machine learning, Nature 2025
[11] H.A. Majid et al, Test-Time Control Over Accuracy-Cost Trade-Offs in Neural Physics Simulators via Recurrent Depth, NeurIPS 2025
[12] H.A. Majid et al, Solaris: A Foundation Model for the Sun, NeurIPS 2024
Abstract:
Oversmoothing is a fundamental challenge in graph neural networks (GNNs): as the number of layers increases, node embeddings become increasingly similar, and model performance drops sharply. Traditionally, oversmoothing has been quantified using metrics that measure the similarity of neighbouring node features, such as the Dirichlet energy. We argue that these metrics have critical limitations and fail to reliably capture oversmoothing in realistic scenarios. For instance, they provide meaningful insights only for very deep networks, while typical GNNs show a performance drop already with as few as 10 layers.
...
Read more
Abstract:
The COVID-19 pandemic shifted academic collaboration from in-person to remote interactions. This study explores, for the first time, the effects on scientific collaborations and impact of such a shift, comparing research output before, during, and after the pandemic. Using large-scale bibliometric data, we track the evolution of collaboration networks and the resulting impact of research over time. Our findings are twofold: first, the geographic distribution of collaborations significantly shifted, with a notable increase in cross-border partnerships after 2020, indicating a reduction in the constraints of geographic proximity.
...
Read more
First place at the ACM ICAIF 2025 Cryptocurrency Forecasting Competition
Huge congratulations to PhD students Kevin Zhang and Denis Zorba for winning first place at the ACM ICAIF 2025 Cryptocurrency Forecasting Competition, a flagship international challenge in AI for Finance, under team name “8k3”! They defeated approximately 130 competitors and 740 submitted models.
Their winning approach demonstrates the power of neural oscillators as architectures for time series forecasting. They successfully turned our recent research paper on GNN neural oscillators into a top-performing cryptocurrency forecasting model.
They received praise for their “advanced approaches and innovative solutions for cryptocurrency forecasting” and have presented their work orally at the ICAIF 2025 Award Ceremony on November 16, 2025, at the Sheraton Towers Singapore.
Abstract:
Recent work in deep learning has opened new possibilities for solving classical algorithmic tasks using end-to-end learned models. In this work, we investigate the fundamental task of solving linear systems, particularly those that are ill-conditioned. Existing numerical methods for ill-conditioned systems often require careful parameter tuning, preconditioning, or domain-specific expertise to ensure accuracy and stability. In this work, we propose Algebraformer, a Transformer-based architecture that learns to solve linear systems end-to-end, even in the presence of severe ill-conditioning.
...
Read more
Abstract:
Generalized friendship paradoxes occur when, on average, our friends have more of some attribute than us. These paradoxes are relevant to many aspects of human interaction, notably in social science and epidemiology. Here, we derive new theoretical results concerning the inevitability of a paradox arising, using a linear algebra perspective. Following the seminal 1991 work of Scott L. Feld, we consider two distinct ways to measure and compare averages, which may be regarded as global and local.
...
Read more
Abstract:
Oscillatory Graph Neural Networks (OGNNs) are an emerging class of physics-inspired architectures designed to mitigate oversmoothing and vanishing gradient problems in deep GNNs. In this work, we introduce the Complex-Valued Stuart-Landau Graph Neural Network (SLGNN), a novel architecture grounded in Stuart-Landau oscillator dynamics. Stuart-Landau oscillators are canonical models of limit-cycle behavior near Hopf bifurcations, which are fundamental to synchronization theory and are widely used in e.g. neuroscience for mesoscopic brain modeling.
...
Read more
Congratulations Arturo!
Congratulations to Arturo De Marinis for successfully defending his PhD thesis on “Stability and Approximation Properties of Neural Ordinary Differential Equations” at the Gran Sasso Science Institute (GSSI)! It has been a pleasure to work with Arturo and I look forward to seeing the next steps in his career.
Abstract:
We study the collective dynamics of coupled Stuart–Landau oscillators, which model limit-cycle behavior near a Hopf bifurcation and serve as the amplitude-phase analogue of the Kuramoto model. Unlike the well-studied phase-reduced systems, the full Stuart–Landau model retains amplitude dynamics, enabling the emergence of rich phenomena such as amplitude death, quenching, and multistable synchronization. We provide a complete analytical classification of asymptotic behaviors for identical natural frequencies, but heterogeneous inherent amplitudes in the finite- setting.
...
Read more
Abstract:
Accuracy-cost trade-offs are a fundamental aspect of scientific computing. Classical numerical methods inherently offer such a trade-off: increasing resolution, order, or precision typically yields more accurate solutions at higher computational cost. We introduce \textbf{Recurrent-Depth Simulator} (\textbf{RecurrSim}) an architecture-agnostic framework that enables explicit test-time control over accuracy-cost trade-offs in neural simulators without requiring retraining or architectural redesign. By setting the number of recurrent iterations $K$, users can generate fast, less-accurate simulations for exploratory runs or real-time control loops, or increase $K$ for more-accurate simulations in critical applications or offline studies.
...
Read more
My talk on “Low-rank geometry in deep learning” discusses network compression and efficient training through low-rank approaches, exploring how deep networks exhibit an implicit low-rank bias and presenting geometry-aware gradient descent methods with theoretical convergence guarantees.
More information about the event and my talk can be found on the SOCN website.
Paper accepted @ SIAM Journal on Mathematical Analysis
This work introduces a novel spectral method for simultaneously detecting core-periphery structures in both nodes and layers of multilayer networks. The method reveals fascinating structural insights across diverse real-world networks, from the citation network of complex network scientists to European airline transport and world trade networks. Physical Review Letters is one of the most prestigious venues in physics, making this acceptance particularly exciting for advancing the field of network science.
You can find the full paper here and the preprint on arXiv.
Abstract:
We introduce a nonlinear extension of the joint spectral radius (JSR) for switched discrete-time dynamical systems. The classical JSR characterizes the exponential growth rate of linear switched systems, but its extension to nonlinear systems has remained an open problem. Our approach builds on the framework of nonlinear Perron-Frobenius theory to define a meaningful notion of joint spectral radius for nonlinear switched systems. We establish fundamental properties of this nonlinear JSR, including its relationship to the stability of switched nonlinear systems, and provide computational methods for its approximation.
...
Read more
Abstract:
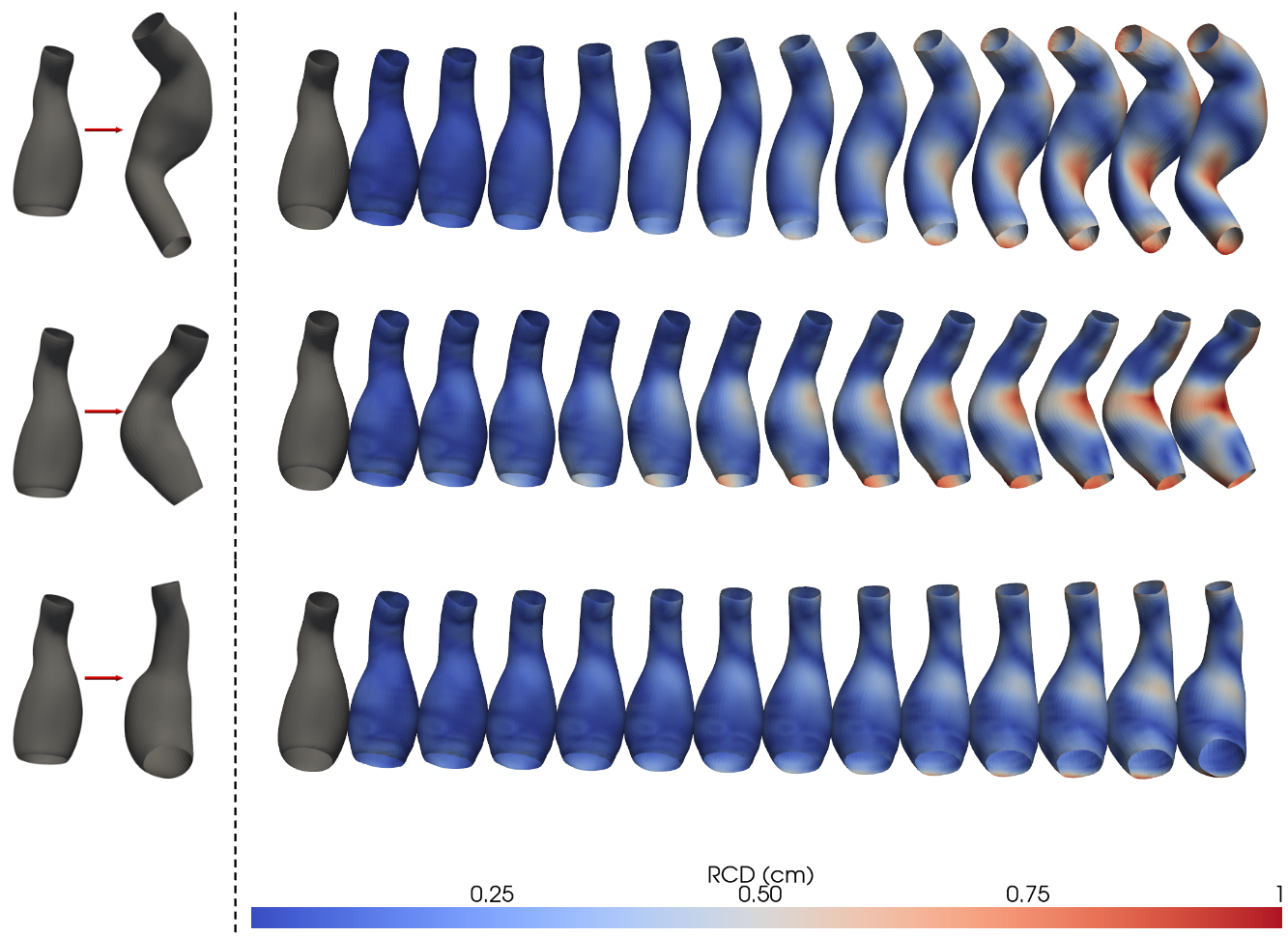
Synthetic data generation plays a crucial role in medical research by mitigating privacy concerns and enabling large-scale patient data analysis. This study presents a beta-Variational Autoencoder Graph Convolutional Neural Network framework for generating synthetic Abdominal Aorta Aneurysms (AAA). Using a small real-world dataset, the approach extracts key anatomical features and captures complex statistical relationships within a compact disentangled latent space. To address data limitations, low-impact data augmentation based on Procrustes analysis was employed, preserving anatomical integrity.
...
Read more
--- The left column shows the ground truth aneurysm meshes, while the right column presents the intermediate shapes generated by interpolating between latent representations. The color map encodes the root Chamfer distance (RCD), illustrating how the geometry transitions smoothly between the original and interpolated states.
Congratulations Dayana!
Congratulations to Dayana Savostianova for successfully defending her PhD thesis at the Gran Sasso Science Institute (GSSI)! It has been a pleasure to work with Dayana and I look forward to seeing the next steps in her career.
Hidden Structures in Dynamical Systems, Optimisation and Machine Learning
Very happy to be organizing the workshop Hidden Structures in Dynamical Systems, Optimisation and Machine Learning this week at the Gran Sasso Science Institute in L’Aquila, as part of the thematic programme on Hidden Structures in Dynamical Systems.
The event brings together researchers working at the intersection of numerical analysis, dynamical systems, optimization, and machine learning, with a focus on uncovering and leveraging latent geometric or algebraic structures in complex models.
All the details can be found at the official workshop page:
Thrilled to share that our COST Action project mSPACE – multiscale Stochastics, Patterns, and Analysis of Combinatorial Environments (CA24122) has been selected for funding by COST!
mSPACE aims to develop a rigorous mathematical foundation for the study of multiscale systems, which emerge in both natural and synthetic contexts due to complex interactions across discrete, continuous, and hybrid domains.
We will explore:
Large-scale and long-time behavior in systems with randomness and geometry
Applications to microstructure optimization, biological systems, and transport networks
Interdisciplinary connections bridging mathematics, materials science, and machine learning
This project brings together a vibrant, interdisciplinary community from across Europe and is committed to equity, inclusion, and broad engagement, including support for female and junior researchers and participation from countries with emerging research programs.
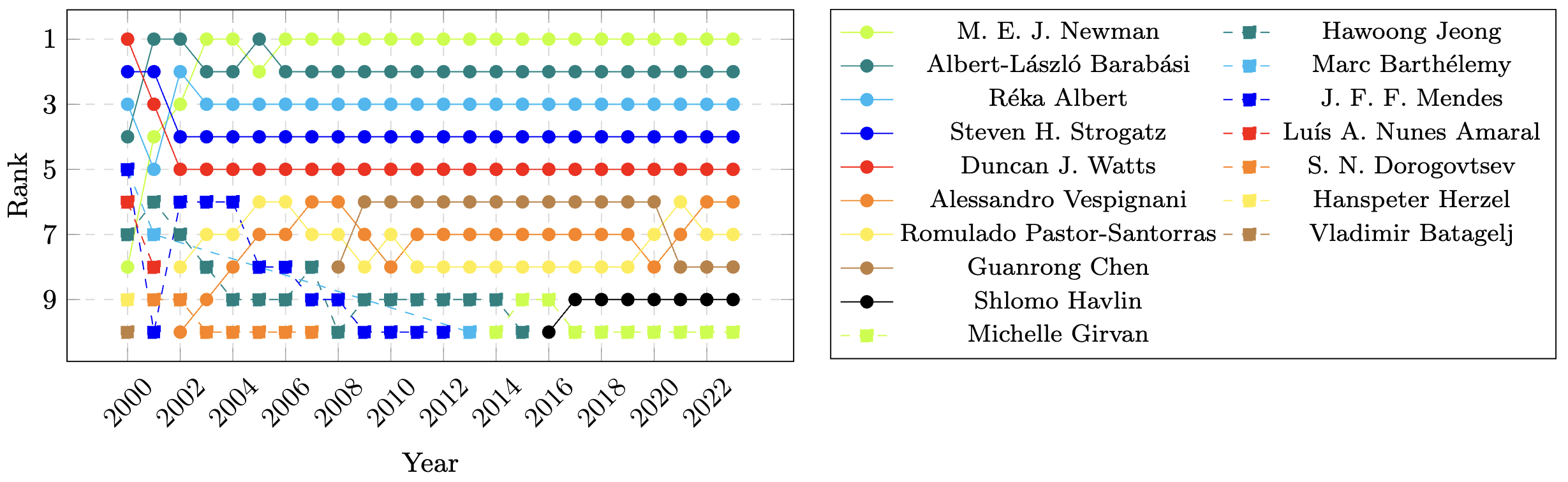
Abstract:
Multilayer networks provide a powerful framework for modeling complex systems that capture different types of interactions between the same set of entities across multiple layers. Core-periphery detection involves partitioning the nodes of a network into core nodes, which are highly connected across the network, and peripheral nodes, which are densely connected to the core but sparsely connected among themselves. In this paper, we propose a new model of core-periphery structure in multilayer networks and a nonlinear spectral method that simultaneously detects the corresponding core and periphery structures of both nodes and layers in weighted and directed multilayer networks.
...
Read more
--- Top 10 authors by node coreness score in the weighted OpenAlex citation multilayer network over the years 2000 to 2023
Presenting Our Work at ICLR 2025
I’m excited to share that our research group is presenting two papers this week at the International Conference on Learning Representations (ICLR) in Singapore!
Emanuele Zangrando is attending the conference in person to present our latest work on efficient low-rank fine-tuning techniques for deep neural networks. If you’re at ICLR, come visit us during the poster sessions and let’s talk shop!
Poster Sessions:
GeoLoRA: Geometric integration for parameter-efficient fine-tuning
📍 Friday – Hall 3 + Hall 2B, Poster #457
🔗 Read the paper
dEBORA: Efficient Bilevel Optimization-based low-Rank Adaptation
📍 Saturday – Hall 3 + Hall 2B, Poster #426
🔗 Read the paper
A big thank you to all my fantastic collaborators:
Emanuele Zangrando, Steffen Schotthoefer, Jonas Kusch, Gianluca Ceruti, Sara Venturini, and Francesco Rinaldi.
Looking forward to engaging conversations and feedback from the community!
Abstract:
Nonlinear spectral graph theory is an extension of the traditional (linear) spectral graph theory and studies relationships between spectral properties of nonlinear operators defined on a graph and topological properties of the graph itself. Many of these relationships get tighter when going from the linear to the nonlinear case. In this manuscript, we discuss the spectral theory of the graph p-Laplacian operator. In particular we report links between the p-Laplacian spectrum and higher-order Cheeger (or isoperimetric) constants, sphere packing constants, independence and matching numbers of the graph.
...
Read more
Abstract:
We study the approximation properties of neural ordinary differential equations (neural ODEs) in the space of continuous functions. Since a neural ODE requires input and output dimensions to be the same, while input and output dimensions of a continuous function are generally different, we need to embed an input into the latent space of the neural ODE, and to project the output of the neural ODE into the output space. By composing the neural ODE flow map with such embedding and projection operations, we get a shallow neural network whose activation function is defined as the flow map of the neural ODE at the final time of the integration interval.
...
Read more
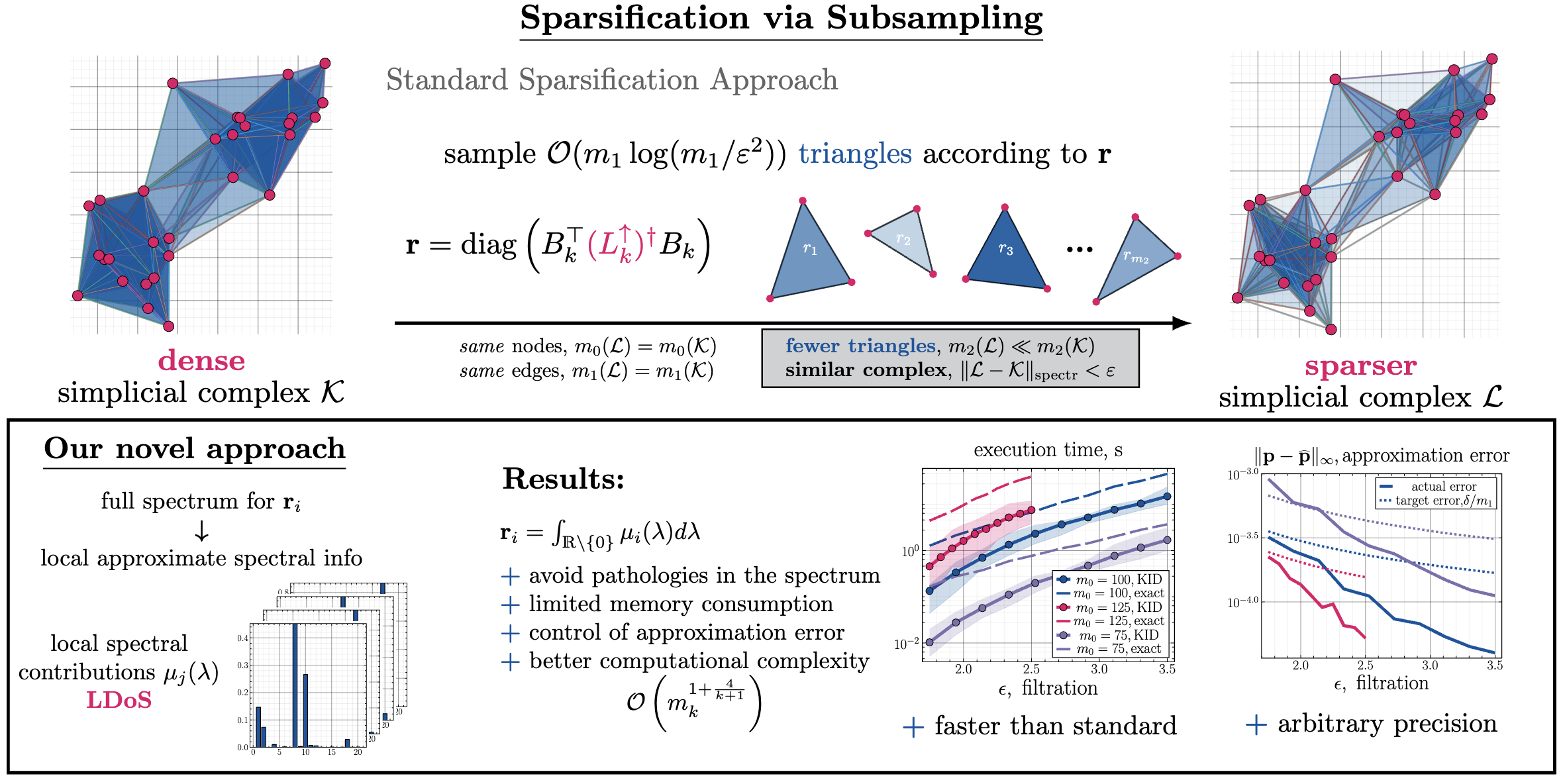
Abstract:
Simplicial complexes (SCs), a generalization of graph models for relational data that account for higher-order relations between data items, have become a popular abstraction for analyzing complex data using tools from topological data analysis or topological signal processing. However, the analysis of many real-world datasets leads to dense SCs with a large number of higher-order interactions. Unfortunately, analyzing such large SCs often has a prohibitive cost in terms of computation time and memory consumption.
...
Read more
--- Schematic example of the efficient sparsification of a simplicial complex $K$ at the level of triangles.
Papers accepted @ ICLR 2025
Excited to share that two of my papers have been accepted at ICLR 2025! 🎉🚀
Abstract:
We propose a method to enhance the stability of a neural ordinary differential equation (neural ODE) by reducing the maximum error growth subsequent to a perturbation of the initial value. Since the stability depends on the logarithmic norm of the Jacobian matrix associated with the neural ODE, we control the logarithmic norm by perturbing the weight matrices of the neural ODE by a smallest possible perturbation (in Frobenius norm). We do so by engaging an eigenvalue optimisation problem, for which we propose a nested two-level algorithm.
...
Read more
Abstract:
Oversmoothing is a fundamental challenge in graph neural networks (GNNs): as the number of layers increases, node embeddings become increasingly similar, and model performance drops sharply. Traditionally, oversmoothing has been quantified using metrics that measure the similarity of neighbouring node features, such as the Dirichlet energy. While these metrics are related to oversmoothing, we argue they have critical limitations and fail to reliably capture oversmoothing in realistic scenarios. For instance, they provide meaningful insights only for very deep networks and under somewhat strict conditions on the norm of network weights and feature representations.
...
Read more
Computational Aspects of Complex Networks
I am giving a talk today on our recent work on fast preconditioning of higher-order Laplacians from simplicial complexes using the topology of the complex at the CACN Computational Aspects of Complex Networks workshop at the University of Rome Tor Vergata. Thanks Maria Rosa and Daniele for the kind invitation!
Thrilled to join the Generative AI Lab (GAIL) at the University of Edinburgh as a GAIL Fellow! Looking forward to the exciting journey ahead 🚀✨ gail.ed.ac.uk