My research interests lie at the intersection between matrix theory, scientific computing, network analysis and machine learning. In my work I develop new theorems and accompanying computational tools to address issues which originate from real-world applications that involve data streams.
In particular, some of the fields I am currently working on are: low-parametric machine learning, higher-order data mining, graph-based unsupervised and semi-supervised learning, community and core-periphery detection in networks, spectral theory for discrete graphs, nonlinear Perron-Frobenius theory, tensor methods and tensor eigenvectors, multilayer graph clustering and centrality.
I outline below some of the research themes I am currently working on.
Nonlinear eigenvectors in data mining
An eigenvector-dependent nonlinear eigenvalue problem or,
more briefly, a nonlinear eigenvector problem, has
the form
\begin{equation}\label{eq:fft:NEvP}
A(x)x = \lambda B(x)x,
\end{equation}
where $A,B:\mathbb R^n\to\mathbb R^{n\times n}$ are matrix valued functions. The linear (generalized) eigenvector problem is retrieved when both $A$ and $B$ are constant matrices. This type of eigenvector problem arises in many contexts, including quantum chemistry, physiscs, medical engineering, image processing.
In my work I am particularly interested in applications of \eqref{eq:fft:NEvP} to data mining and machine learning problems such as unsupervised and semi-supervised learning, link prediction, anomaly detection, centrality and feature selection for both static and time-evolving datasets.
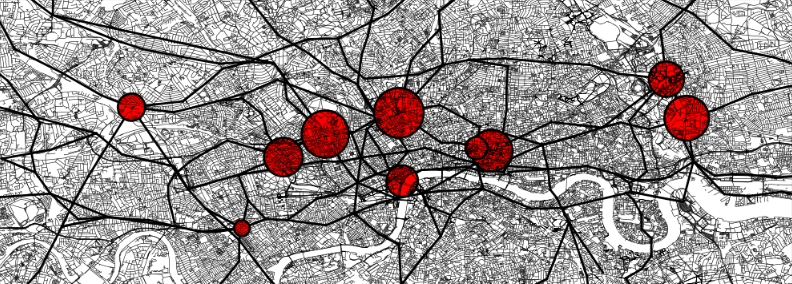
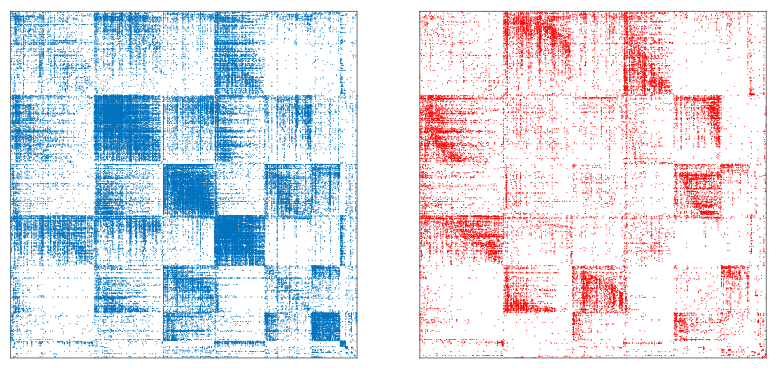
Networks and graphs are a very powerful modeling tool to address a range of data science problems. For example, in exploratory data analysis we are often interested in finding clusters or communities, or assessing the importance (or centrality) of datapoints.
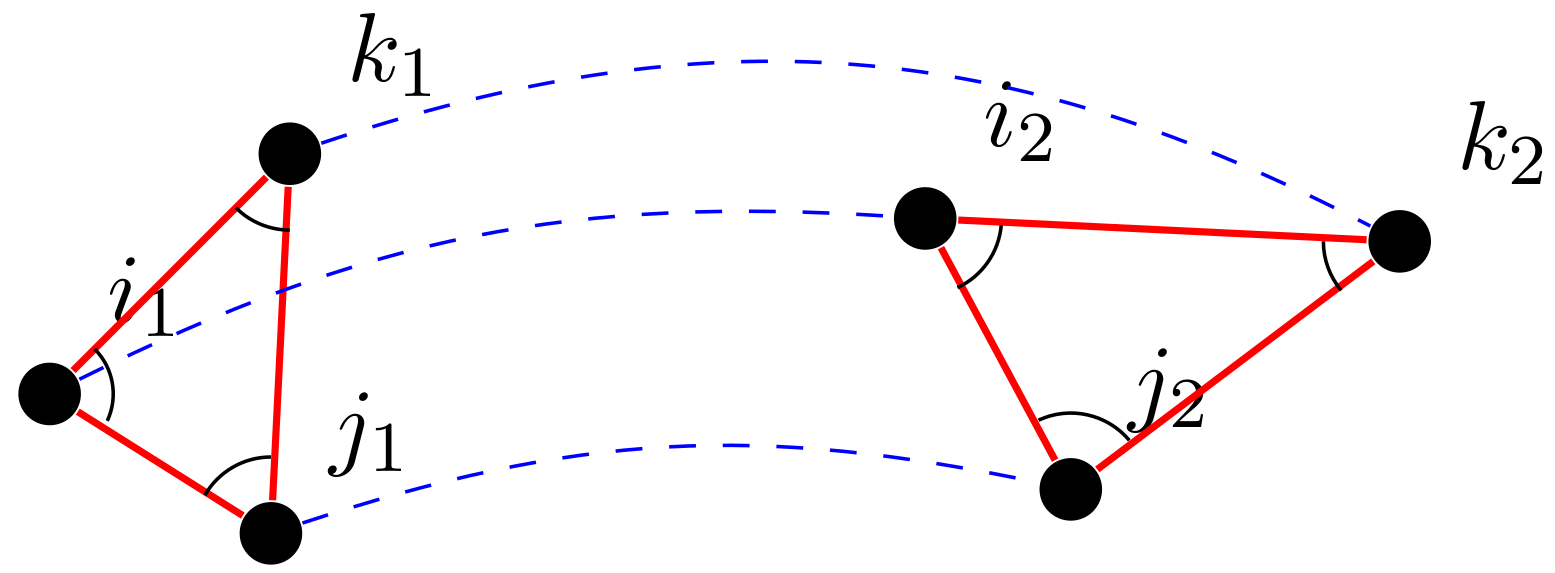
I am interested in developing both theoretical foundations and efficient algorithms for a range of network analysis problems and I am particularly interested in methods that exploit matrix and tensor representations of the data to approximately solve related combinatorial optimization problems. In particular, I am very interested in higher-dimensional graph models. These models arise very naturally in modern data
processes, as many real-world datasets feature geographical, temporal, or categorical metadata and higher-order
structures (motifs) and interactions (beyond standard pairwise node-edge connections).
You may wish to have a look at the following brief introductory video by Michael Schaub:
I use techniques from spectral theory, tensor analysis, and computational mathematics to develop
methods that exploit spectral information to solve problems such as identifying hidden structures and quantifying important components in large data.
An operator $f:\mathbb R^n\to \mathbb R^m$ is multihomogeneous if there exist a partition of the input variable $x = (x_1,\dots,x_d)$, $x_i \in \mathbb R^{n_i}$ with $n_1+\dots+n_d=n$, and $m\times d$ coefficients $a_{ij}$ such that
$$
f(x_1,\dots, \lambda x_j, \dots, x_d)_i = \lambda^{a_{ij}} f(x_1, \dots, x_d)_i
$$
for all $i=1,\dots,m$.
Multihomogeneous operators extend the better known concept of homogeneous mappings, which is retrieved when $d = 1$ in the definition above. In that case we have $a_{ij} = a \in \mathbb R$ and we usually say that $f$ is a homogeneous map of degree $a$. Generalizing the bautiful nonlinear Perron-Frobenius theory, we introduced the notion of multihomogeneous mapping as a general setting of mappings for which a nonlinear version of the Perron-Frobenius theorem holds. Multihomogeneous mappings appear in numerous applications. For example, eigenvector and singular vector problems for tensors $T=(t_{i_1,\dots,i_m})$, can be written in terms of suitable multihomogeneous operators.
The study of multihomogeneous operators has numerous open research problems which can lead to important applications to data science.